인공지능?
'인공지능'하면 가장 먼저 떠오르는 것은 무엇인가요? 무인으로 운행되는 자율주행자동차, 인공지능 바둑프로그램인 알파고를 떠올리셨나요? 우리의 삶과 약간 동떨어진 최첨단 기술을 떠올리셨군요. 하지만 우리는 이미 일상생활에서 다양한 인공지능을 활용하고 있습니다.
핸드폰 카메라로 사진을 찍을 때 피사체를 자동으로 감지하고 필터를 보정해 주는 것
예전 구매한 쇼핑 목록을 통해 다른 상품을 추천해 주는 것
스팸메일을 자동으로 분류해주는 것
우리의 일상생활 속에서 사용하고 있는 여러 기술에 이미 인공지능이 활용되고 있습니다.
인공지능의 개념과 기계학습의 학습방식
인공지능, 기계학습, 딥러닝은 서로 간에 포함관계를 가지고 있습니다. 인공지능이라는 전체집합 안에 기계학습이 포함되고, 기계학습 안에 딥러닝이 포함되는 관계를 가지고 있습니다. 인공지능이란 인간의 지능(학습능력, 추론능력, 지각능력)을 인공적으로 구현하려는 컴퓨터 과학기술을 말합니다. 기계학습은 주어진 데이터를 사용하여 기계가 스스로 학습하게 하는 방법으로 빅데이터의 발전에 따라 더욱 주목받고 있는 기술입니다. 영어식 표현으로 '머신러닝'이라고 합니다. 교육과정에서는 '기계학습'으로 사용됩니다.

'컴퓨터가 스스로 학습한다'는 말은 무엇일까요? 일반적인 프로그래밍일 경우 사람이 직접 컴퓨터에 규칙을 입력하는 것입니다. 그러나 기계학습일 경우에는 입력값과 출력값 사이의 관계를 이어주는 최적의 함수를 찾는 과정, 즉 학습한 규칙을 새로운 자료에 적용하여 판단하고 예측할 수 있습니다. 기계학습의 특징은 데이터를 기반으로 스스로 학습한다는 것입니다.
컴퓨터가 스스로 알맞은 규칙을 찾을 수 있도록 하는 기계학습에는 다양한 학습방법이 있습니다.
기계학습의 학습방법
지도학습, 비지도학습, 강화학습
(1) 지도학습 : 인공지능에게 문제와 정답을 모두 알려 주고 학습시키는 방법으로 레이블 된 데이터를 학습시킨 후, 새로운 데이터가 무엇인지 판단하게 하는 방법입니다. 지도학습에는 분류와 예측이 있습니다. 분류란 유사한 특성을 가진 데이터끼리 묶어서 그룹을 짓는 방법이고, 예측은 학습 데이터를 기반으로 새로운 입력값에 대한 합리적인 출력값을 도출하는 것입니다.
▶ 단점 : 학습시킬 데이터에 레이블을 입력한다는 번거로움이 있습니다. 레이블 입력에는 많은 시간과 비용이 소모되기 때문입니다.
(2) 비지도학습 : 정답을 알려주지 않고 학습시키는 방법으로 인공지능이 스스로 데이터의 특성을 파악하여 군집화합니다. 군집화란 전체 데이터 중에서 비슷한 특성을 보이는 데이터들을 몇 가지의 군집으로 나누는 방법입니다. 이것은 지도학습의 분류와 비슷해 보이지만 차이점이 있습니다. 분류는 레이블을 기반으로 데이터를 나눠 새로운 데이터가 어떤 레이블에 속하는지 판단하는 것에 초점이 있다면, 군집화는 레이블이 없는 데이터를 유사성에 따라 어떻게 묶일 수 있는지에 대해 파악합니다. 따라서 비지도 학습의 군집화 방식은 사람이 분류 기준을 명확히 제시하기 어려운 분야에 적합합니다. 이러한 군집화의 대표적 사례에는 비슷한 특징을 가지 사람을 그룹화하여 특성에 맞게 추천해 주는 서비스에 활용됩니다. 예를 들어, 온라인 쇼핑몰 상품 추천, 동영상 플랫폼 영상 추천 등이 있습니다. 또한 정답을 달기 힘든 데이터를 비지도 학습을 이용해 그룹으로 묶고, 묶은 데이터를 레이블링하여 지도학습을 위한 데이터로 사용할 수 있습니다.
이와 같은 군집화는 한 번에 되는 것이 아니라 여러 번에 걸쳐 이루어집니다. 처음에는 군집을 나누는 기준이 없이 때문에 나누고자 하는 개수만큼의 임의로 군집 중심점을 설정합니다. 이때 각 데이터가 어느 군집 중심점과 가까운지 확인할 수 있습니다. 이후 데이터마다 해당하는 군집이 설정되면 그 군집 내 데이터의 평균으로 군집 중심점을 이동합니다. 군집 중심점으로부터 거리에 따라 군집을 재설정합니다. 이 과정을 반복하여 더 이상 군집의 중심점이 옮겨지지 않을 때 비로서 군집화는 완성이 됩니다.
(3) 강화학습 : 인공지능에게 보상 또는 불이익을 주어 학습시키는 방법입니다. 이는 행동심리학에서 영감을 받은 것으로 특정행동을 강화하기 위한 보상과 특정행동을 하지 않도록 만드는 불이익을 통해 더 많은 보상을 받을 수 있는 방향으로 행동이 점점 강해지는 것입니다. 가장 대표적인 예로는 인공지능 바둑 프로그램인 '알파고'가 있습니다. '알파고' 는 프로기사들의 기보 16만 건을 바탕으로 한 지도학습과 수십만 것의 자체 대국을 통한 강화학습으로 만들어진 인공지능 프로그램입니다.
이후, 구글 딥마인드 연구진은 기보를 학습하는 것이 아니라 오직 바둑의 규칙만을 알려주고 강화 학습만을 시킨 '알파제로'를 개발하였습니다. '알파제로'는 처음에는 게임 초보자와 같은 모습을 보였으나 30시간의 강화학습 이후에는 '알파고'를 넘어섰습니다. 이처럼 적절한 보상과 벌칙을 부여한 강화학습을 통해 스스로 시행착오를 통해 규칙을 터득하고 새로운 전략을 발견하기도 합니다.
딥러닝이란?
딥러닝이란 기계학습의 한 분야로 인공신경망을 이용하여 기계가 스스로 학습할 수 있도록 만드는 기술입니다. 여기서 인공신경망이란 사람의 뇌 속에 있는 신경망의 원리를 모방하여 만든 수학적 모델을 말합니다. 우리는 신경세포 하나를 뉴런이라고 합니다. 뉴런은 '가지돌기'를 통해서 여러가지 입력신호를 받고 '축삭돌기'를 통해 자극을 전달합니다. 그리고 반응을 일으키는 최소한의 자극의 세기를 넘어서면 활성화되어 신호를 다른 뉴런으로 전달합니다. 이처럼 인간의 뇌는 1000억 개가 넘는 뉴런으로 이루어져 있으며 이런 뉴런들의 연결을 'Neural network', 즉 신경망이라고 합니다. 이것을 모방하여 수학적으로 표현하면 다음과 같습니다.
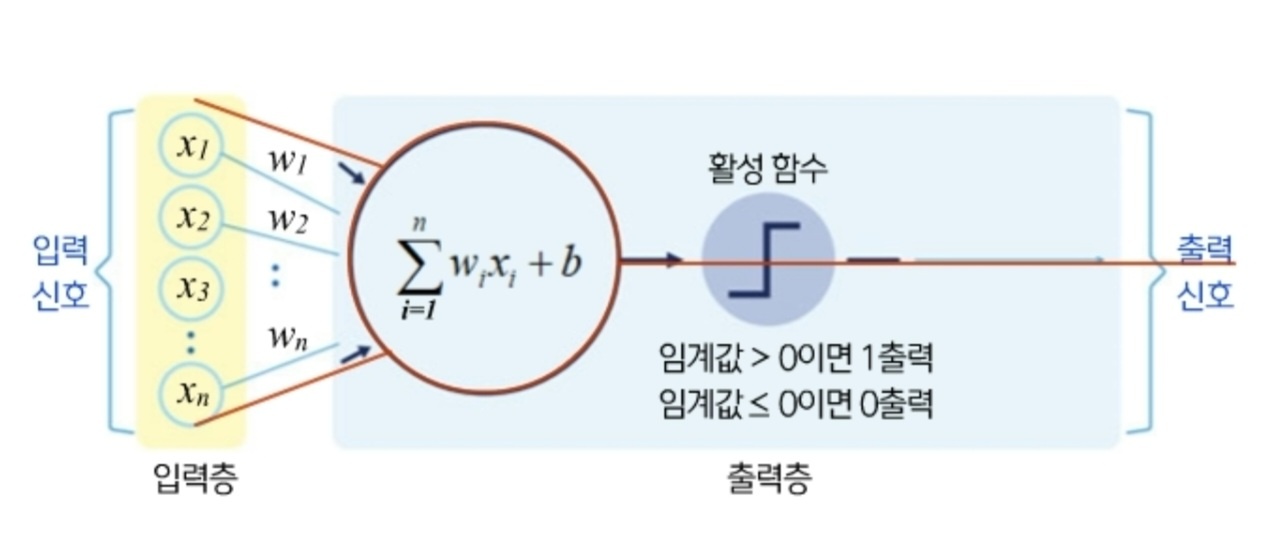
뉴런을 수학적으로 모델화 한 기본단위를 노드라고 합니다. 노드를 서로 연결하여 인간의 신경망같이 나타낸 것을 인공신경망이라고 부릅니다. 또한, 이렇게 입력한 값을 하나의 값으로 만들때는 가중치를 곱하여 각각 더하게 됩니다. 입력된 신호중 데이터를 잘 나타내는 값은 큰 가중치를 곱하고 데이터를 잘 나타내지 못하는 값에는 작은 가중치를 곱하여 각각을 더함으로써 데이터의 특성을 파악하는 것입니다. 그런 다음 가중치를 곱하여 각각을 더한 값을 '활성화함수'라는 것을 통해 출력됩니다. 대표적인 활성화함수로는 'step function', 즉 '계단함수'가 있습니다. 활성화함수에는 0과 1 사이의 값을 모두 치역으로 가지는 '시그모이드'라는 함수도 있습니다. 인공지능을 잘 학습시키는 것으로 알려져 있는 활성화함수로는 렐루함수(ReLU:Rectified Linear Unit)가 있습니다.
입력신호와 활성함수는 우리가 입력 및 선택하는 것이라면 최적의 가중치를 찾는 일이 인공지능의 역할입니다. 즉 최적의 가중치를 찾는 과정을 바로 학습(leaning)이라고 하는 것입니다. 이러한 인공신경망에서 입력값을 나타내는 부분을 입력층(Input layer)이라 하고, 출력값을 나타내는 부분을 출력층(Output layer)라고 합니다. 특히, 출력값은 하나만 있는 것이 아니고 여러 개 존재할 수 있습니다. 하지만 이처럼 많은 것을 분류하는 경우에는 중간 과정이 조금 더 필요합니다. 따라서 노드를 추가로 연결해야 하며 이때 가운데 생기는 층을 은닉층(Hidden layer)이라고 합니다. 은닉층의 개수가 많을수록 인공신경망이 '깊어졌다(deep)'라고 부릅니다. 일반적으로 은닉층이 두 개 이하일 때는 얕은 인공신경망, 은닉층의 개수가 3개 이상일 때는 깊은 인공신경망이라고 부릅니다.
이러한 깊은 인공신경망을 통해 기계가 스스로 학습할 수 있도록 만드는 기술이 '심층학습', 즉 '딥러닝' 입니다. ■
'인공지능 수학' 카테고리의 다른 글
| 인공지능의 역사, 1970년대 인공지능 암흑기 (0) | 2024.02.27 |
|---|---|
| 공학적 도구(티처블머신)를 사용하여 인공지능 체험하기 (0) | 2024.02.26 |
| <인공지능 수학>의 개관 (0) | 2024.02.24 |


